Projects
COVID19 Case Outcome Prediction
Projects
Outcome Predictions
For the capstone project for my data science course, myself, paired with two classmates built four models (XGBoost, Catboost, Knn, Random Forest) to predict the outcome of covid 19 cases.
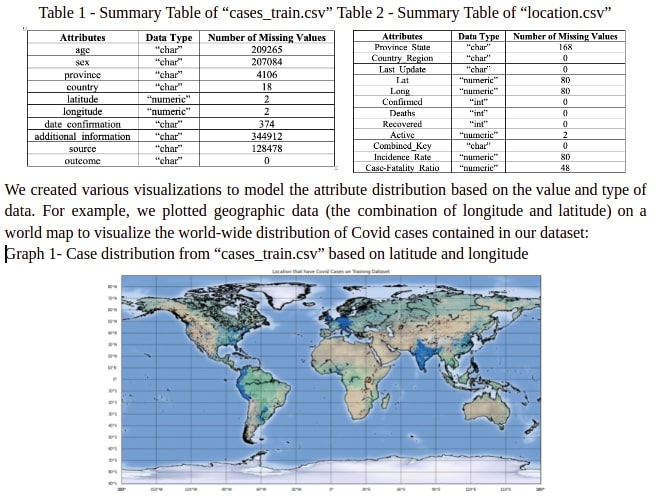
Our dataset was relatively dirty and incomplete, so it took a lot of cleaning up and imputation to get it workable. It was also weak in the quality of the data collected for each case. The most deterministic attributes for any individual were age, and location (given in longitude, latitude). But we had this data for over half a million anonymized individuals and were forced to work with this particular dataset.
I crafted the Knn and XGBoost models. I used the SciPy and Scikit-Learn libraries for both of them. Of course, with heavy use of Pandas and NumPy as well. The largest issue I faced when building these models was the runtime for Knn. I had reduced my hot-encoded data from some forty-dimensional to about twelve dimensional. I had mistakenly assumed that this reduction would simplify the distance calculation enough to make it feasible. But it didn't. It took over two hours for the Knn model to predict the outcome labels on the dataset.
Even after further optimizations, Knn was too slow, so I chose to abandon the model, and switch to XGBoost instead. XGBoost is an extremely popular boosting tree model. It is well-liked for its speed and has a multitude of parameters for tuning that can help increase the precision and recall of predictions.
Unfortunately, XGBoost had a lower than expected F1-Score on the deceased label, which was the minority class in our training set. I attempted to correct this with random undersampling from the training dataset. But knowing what I do now, I wish I had gone with an oversampling approach, as the random undersampling did not correct the F1-Score very impressively. Given the challenges of this dataset, in the future, I would have likely trained multiple XGBoosting models (or even different models) with differing training sets, and taken their overall consensus on the outcome label. At the end of the day, my XGBoost model had about a 20% F1-Score on the deceased label, 99% on non-hospitalized, and 76% on hospitalized.